Projects
GPU inference engines, custom CUDA kernels, and AI-agent systems I've built or am actively working on.
-
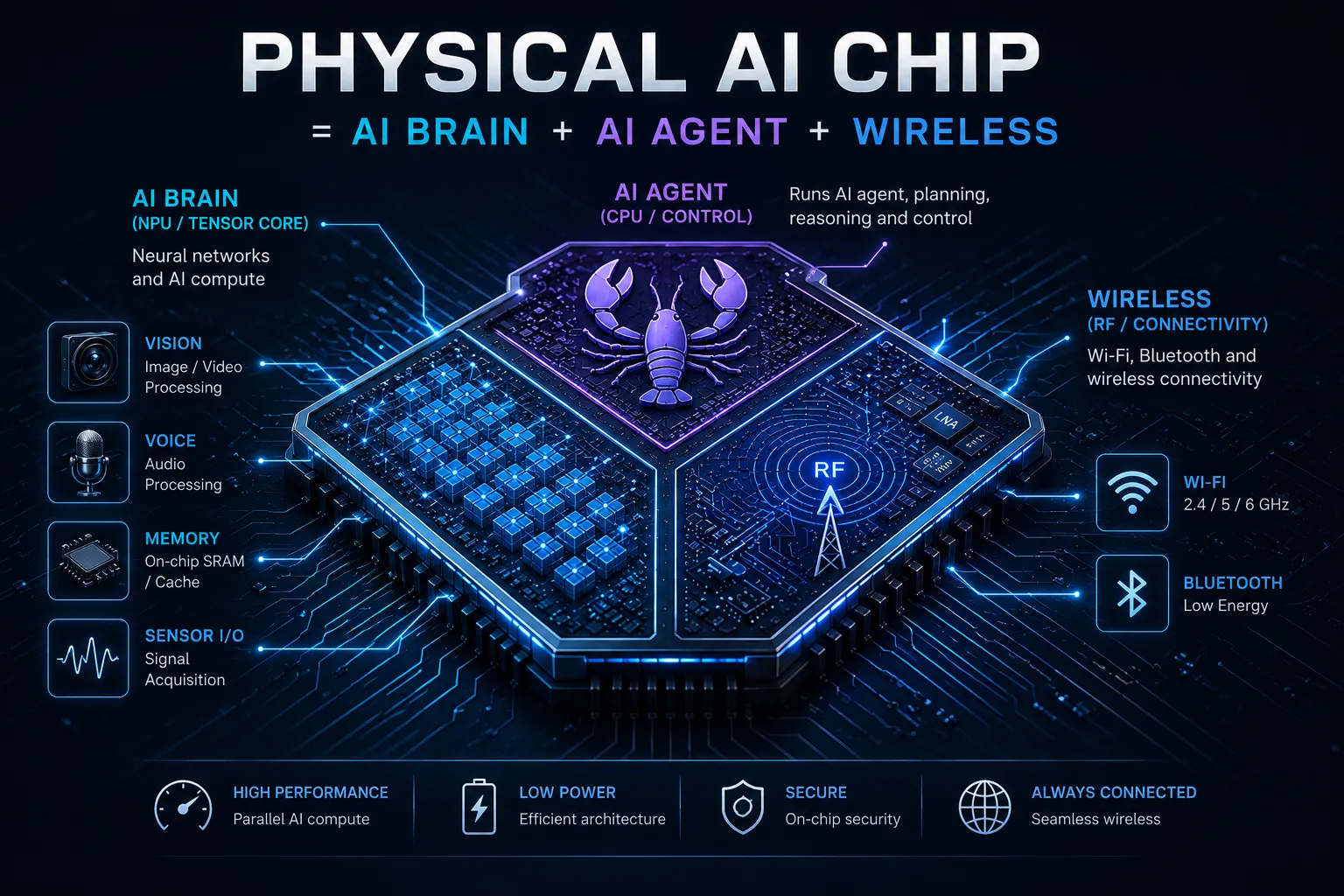
ai-hardware-engineer-roadmap
ActiveMy public learning roadmap and living resume — the path from AI inference to agent harness systems to hardware engineering, aimed at designing a physical AI chip. 200+ GitHub stars.
- Roadmap
- Physical AI
- AI Chip
-

genie-ai-runtime
ActiveA from-scratch AI inference engine for the NVIDIA Jetson Orin Nano, specialized for Qwen 3.5 4B and powering the GeniePod product — measurably faster than llama.cpp on the same hardware.
- Jetson Orin Nano
- Inference Engine
- CUDA
-

hopper-qwen-72b
ActiveHand-written CUDA kernels serving Qwen 2.5 72B Instruct across 2×/4×/8× Hopper GPUs (TP=8), built to beat vLLM throughput — a ground-up study of multi-GPU inference at the kernel level.
- Hopper
- TP=8
- Custom Kernels
Private repository -

triton-vm-prover
CompletedGPU-accelerated zk-STARK prover for Triton VM on the RTX PRO 6000 — 11,000+ lines of C++/CUDA, designed and built from scratch, reaching 10× the throughput of the top-ranked CPU prover.
- CUDA
- zk-STARK
- C++
-

-

genie-claw
ActiveA tailored AI-agent harness for smart-home automation, tuned for low latency, tight context budgets, and higher task accuracy.
- AI Agent
- Smart Home
- Low Latency
-

openclaw
ActiveMaintainer of OpenClaw, a leading open-source AI agent framework — reviewing and shipping changes to the core.
- AI Agents
- Open Source
- Maintainer
More on GitHub: @ai-hpc